Our work on cloud performance management was recently awarded the Test-of-Time award at the ACM/IFIP Middleware Conference held this December at Vanderbilt University. The award is given for a paper that appeared at the conference 10 years or so back and that is considered to have had the greatest impact on the field, be this through follow-on research or influence on product lines in the commercial sector. We were recognized for a paper that appeared in the 2014 edition of the Middleware Conference.
Amiya Maji, Subrata Mitra, Bowen Zhou, Saurabh Bagchi, and Akshat Verma. “Mitigating interference in cloud services by middleware reconfiguration.” In Proceedings of the 15th International Middleware Conference, pp. 277-288. 2014.
While receiving the award, I gave a presentation at the conference looking at what the paper had accomplished and what the state is today of cloud performance management. In this article I describe my thinking on these matters, concluding with what I see are important problems still to be solved.
Some context about our work
The work was started when the lead author, Amiya, went for an internship to IBM Research and then continued that work after he came back to Purdue. Our IBM co-author, Akshat, provided a compelling real-world technical challenge to Amiya and then defined the constraints and the requirements for a credible solution. While developing the solution, Amiya realized he needed more heads for the design and more hands for the implementation and evaluation and that’s how two other PhD students in our group, Subrata and Bowen got involved. We submitted the work to the Middleware 2014 Conference where it was one of 27 regular papers that got accepted, for an acceptance rate of 18.75%. The conference was held in Bordeaux in France, a region famous for its eponymous wine, in December 2014. Amiya and Akshat attended.

State of cloud computing then (circa 2014)
The field of public cloud computing was beginning to establish itself as a major disruption to how computing was done. AWS had been launched back in 2006 and had established itself firmly as the front-runner. Microsoft Azure was a more recent entrant to the field, in 2010, and had set itself up in the second spot. The global market was at $60B — in 2025, it is estimated to be $980B, thus having a CAGR of 29%. Apart from the top two, the other major players were IBM (SoftLayer), Google, Rackspace, and VMWare — of these, only Google survives.
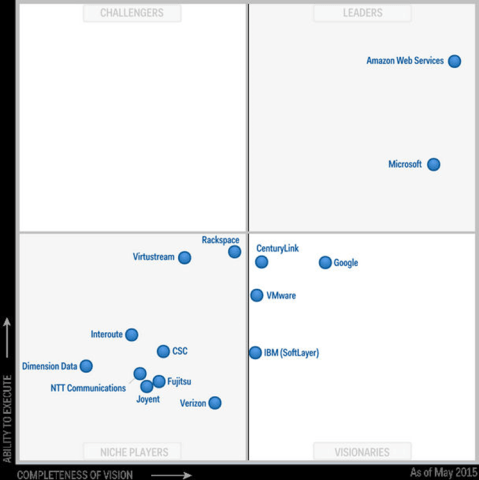
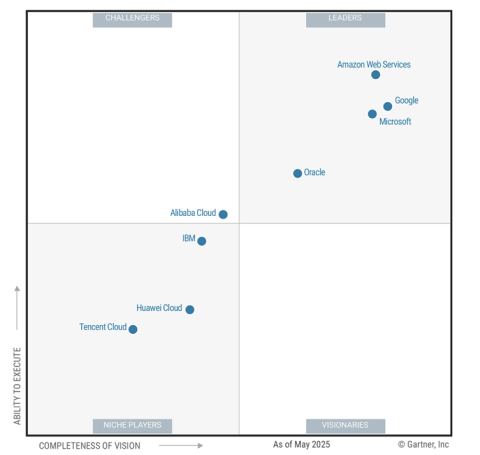
In terms of the use of the cloud computing technology, it was coming into its own establishing itself as a major form of infrastructure for computing, i.e., for processing of computer code. Thus, cloud computing was emerging from the shadows of being used primarily as a data storage mechanism, which was its prime driver in the earlier days. Second, the cloud was starting to be used to serve mobile traffic and the big rise in such traffic volume was just around the corner. In fact, the mobile cloud traffic would grow 11X between 2014 and 2019. Third, there was a rise of hybrid and multi-cloud execution — hybrid means part of the execution happens on the premise and part on the public cloud; multi-cloud means the customer uses cloud computing offerings from multiple providers. This trend has been firmly set by now, with 90% of large and medium-sized organizations in the US having adopted a hybrid cloud approach.
What our Paper Accomplished
The problem statement that our work tackled was that one of the two key impediments to the adoption of cloud computing was found to be concern about performance when migrating applications from on-premise computing to the cloud. In a 2013 IDC survey of IT buyers, 40% cited application performance as a key concern. (The other key impediment was operational support for business-critical applications.) So we looked at what are the root causes of unpredictable performance on the cloud. We found two primary reasons.
- Misconfigurations of the elements in the cloud infrastructure, such as, virtual machines (VMs), storage, and networks.
- Imperfect isolation of hardware resources across multiple VMs running on the same physical server.
This second factor is known as performance interference and was the root cause that we set out to tackle.
Within this aspect of performance interference, we found that it is possible with current hardware to effectively partition CPU and memory resources and cloud providers were doing an adequate job of this. However, there were other hardware resources that were impossible to partition using existing hardware functionality — these included primarily cache capacity and memory bandwidth.
The favored solutions that existed at that time did one of three things: (1) better placement of the VMs among the cluster of servers; (2) better scheduling by the hypervisor of the VMs on any given server; (3) dynamic live migration of VMs from one server to another when interference was detected and was found to be long lasting. All three of these solutions were available to the cloud providers but not to the consumers of the cloud resources. We therefore set out to develop a mechanism that would put control in the hands of the cloud user.
The key idea behind our solution, called IC2, for Interference-aware Cloud application Configuration, was that one can reconfigure one’s application, which is running on the cloud, in reaction to interference. Our paper then answered three key technical questions.
- How to detect interference?
- Which parameters to reconfigure during interference?
- How to determine new parameter values?
We instantiated our solution to the Apache Web Server running on a Python runtime, where three parameters had the greatest effect for reconfiguration — MaxClients, KeepaliveTimeout in Apache webserver and PhpMaxChildren in the PHP runtime. One software contribution was we built on the Apache webserver to create a variant that could be reconfigured online, i.e., when its parameters were changed, the new parameters could be loaded up without needing to shut down and restart the server. Our work showed big gains when there was unpredictable interference that would start up on the physical machine, as we demonstrated on Amazon EC2 as well as our private cloud computing testbed.
Follow-on Work
There are three streams of follow-on work that have built on our idea, that have been most impactful. The first stream is how to choose a cloud VM type for specific applications. In this approach, sometime the application would be reconfigured to achieve a good fit. Two representative papers here are Paper 1 [Yadwadkar SoCC 2017] and Paper 2 [Manco SOSP 2017]. The second stream is how to co-locate multiple types of jobs on the same physical server. This stream of work has gained prominence for co-locating ML workload, batch training with latency-sensitive inferencing. For this, sometime the training jobs would be reconfigured (such as, paused) to reduce the latency of inference. Two representative papers here are Paper 1 [Romero Middleware 2022] and Paper 2 [Mobin HPDC 2023]. And the final stream of work is in a completely different domain, how to approximate computing for streaming ML workloads such that they can run on resource-constrained devices, such as, Internet of Things (IoT) devices or mobile devices or embedded devices. Two representative papers here are Paper 1 (from our group) [Xu SenSys 2020] and Paper 2 [Xiao SEC 2021].
So What are the Pressing Open Problems?
In the current application landscape, I believe the following are the three most pressing directions for our technical community to solve. This is in the broad area of cloud performance management. Each is itself a broad topic, which carries within it several knotty technical problems. I do not mean to suggest that we have not gotten started on these directions — we have realized their importance and have gotten to work on them — but substantive progress remains to be done.

The first direction to explore is how to configure parameters for ML methods. This applies to both training and inference. One instantiation of this is online calibration of the learning hyperparamters, based n how the optimization is going. Another is reconfiguration based on sample characteristics, which is challenging to do because extracting and using the relevant characteristics can itself be a time-consuming task.
The second direction is how to perform auto-correction of detected performance anomalies. Our community has made substantial progress in determination of root causes of performance anomalies, e.g., see this influential series of works and this line of works from our group. But once root cause determination is done, can the performance issue be auto corrected. Some solution approaches readily suggest themselves, such as auto scaling the infrastructure, either horizontally or vertically. Another potential, albeit more speculative, idea is to perform dynamic unlinking of potentially problematic libraries and re-linking to alternate libraries.
The third direction that deserves our attention is how to handle multi-cloud and hybrid deployments. This has been a headache for a while, as many enterprises today use two or more cloud providers and many use an on-premise infrastructure in addition to the cloud. This item has closeted within itself a whole slew of engineering challenges as each provider uses its own distinctive APIs, proprietary metrics, and different names for the same elements. Today it is fiendishly difficult to do integrated or consistent performance management across multiple different cloud infrastructures.
In Conclusion
To sum, the field of cloud performance management had some teething problems back in 2014 and we were at the right time and place to solve one of the important problems. And today, as the demand for cloud computing has risen several folds and the use cases have expanded greatly, there is a universe of technically challenging problems for us to put our brains to.
