This is a high-level view of our work on serverless computing that has just been accepted to Usenix ATC 2021, plus some historical context for why we are where we are. And a look ahead at the rich problems that we still have to tame.
Ashraf Mahgoub (Purdue University), Karthick Shankar (Carnegie Mellon University), Subrata Mitra (Adobe Research), Ana Klimovic (ETH Zurich), Somali Chaterji (Purdue University), Saurabh Bagchi (Purdue University), “SONIC: Application-aware Data Passing for Chained Serverless Applications,” Accepted to appear at the Usenix Annual Technical Conference (USENIX ATC), pp. 1–15, 2021. (Acceptance rate: 64/341 = 18.8%) [ PDF ]
A happy lesson learned was always address the reviewer’s comments, the actionable substantive ones that is. One of the reviewers was a repeat from an earlier submission (to OSDI) and it doubtless helped that we had made major changes in response[1].
Serverless computing platforms provide on-demand scalability and fine-grained allocation of resources. In this computing model, the cloud provider runs the servers and manages all the administrative tasks (e.g., scaling, capacity planning, etc.), while users focus on their application logic. Due to its significant advantages, serverless computing is becoming increasingly popular and is also known by the moniker “Function-as-a-Service” or FaaS[2]. All major cloud providers have serverless products, such as, AWS Lambda, Microsoft Azure Functions, Google Cloud Functions, and IBM Cloud Functions. The global serverless market was $7.6B in 2020 and is projected to grow at a CAGR of 22.7% the next 5 years[3].

Serverless Workflows
One more recent development has been to use serverless computing to support for complex workflows such as data processing pipelines, machine learning pipelines, and video analytics. This involves representing the applications as DAGs (or potentially general graphs) with each node being represented as a function. Accordingly, major cloud computing providers recently introduced their serverless workflow services such as AWS Step Functions, Azure Durable Functions, and Google Cloud Composer, which provide easier design and orchestration for serverless workflow applications. A popular use for serverless workflows is in video analytics and is shown in Fig. 1.
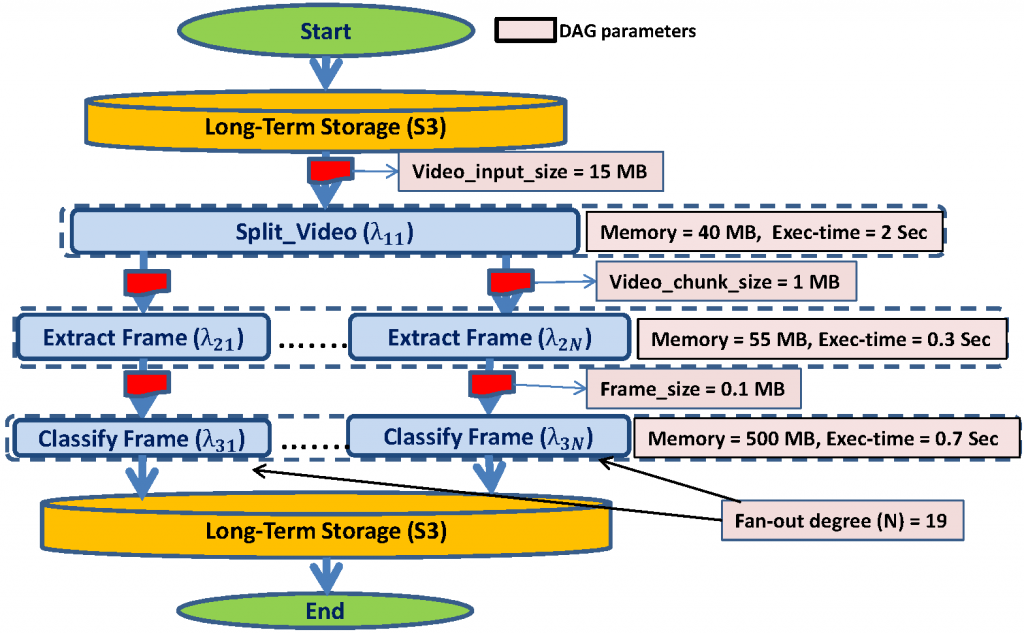
Data Passing among Functions
These workflows obviously create intermediate data between serverless function stages. For example, the “Extract frame” function will do as the name says, extract a representative frame. Then “Classify frame” takes that representative frame and does, as the name says, classifies the frame. Exchanging intermediate data between serverless functions has been a major challenge in serverless workflows. The reason is that, by design, IP addresses and port numbers of individual lambdas are not exposed to users, making direct point-to-point communication difficult. Moreover,
serverless platforms provide no guarantees for the overlap in time between the executions of the parent (sending) and child (receiving) functions.
The way vendors solve this problem today is sending all the data to the storage layer, e.g., AWS S3 or Azure Storage. This has the desired quality that compute and storage are neatly separated. This has the undesired effect that the end-to-end execution time of your application can increase a lot, because writing to and reading from this storage layer is slow. Of course, this slowness is well known in cloud computing circles, but it bites us worse here in the serverless workflow world because each function is short running, the workflow is triggered based on events, and the amount of intermediate data can be large, and unpredictable, in some cases.
SONIC To The Rescue
SONIC was born out of what seemed like a trivially simple idea in December of 2019. We thought of this as a stepping stone to the real meaty technical problems of the day. Little did we know what we would uncover as we started digging. The idea is simply to place lambdas (the serverless functions) with an idea of what their data passing needs are. There are three kinds of data passing options that one can think of (and one does not have to think very hard either).
- One is schedule the sending and receiving functions on the same VM, while preserving local disk state between the two invocations. This is called VM-Storage.
- Second is directly copy intermediate data between the VMs that host the sending and receiving lambdas. This is called Direct-Passing.
- Third is the current state of practice — route data through the storage layer. This is called Remote-Storage.
SONIC decides the best data-passing method for every edge in the application DAG to minimize data-passing latency and cost. We show that this selection can be impacted by several parameters such as the size of input, the application’s degree of parallelism, and VM’s network capacity. SONIC adapts its decision dynamically to changes in these parameters.

Show Me the Results
As our approach requires integration with a serverless platform (and commercial platforms do not allow for such implementation), we integrate SONIC with OpenLambda[4]. We compare SONIC ’s performance using three popular analytics applications: Video analytics, LightGBM, and MapReduce Sort. We compare to several baselines: AWS-Lambda, with
S3 and ElastiCache-Redis (which can be taken to represent state-of-the-practice); SAND[5]; and OpenLambda with S3 and Pocket[6]. Our evaluation shows that SONIC outperforms all baselines. SONIC achieves between 34% to 158% higher performance/$ (here performance is the inverse of latency) over OpenLambda+S3, between 59% to 2.3X over OpenLambda+Pocket, and between 1.9X to 5.6X over SAND, a serverless platform that leverages data locality to minimize execution time.
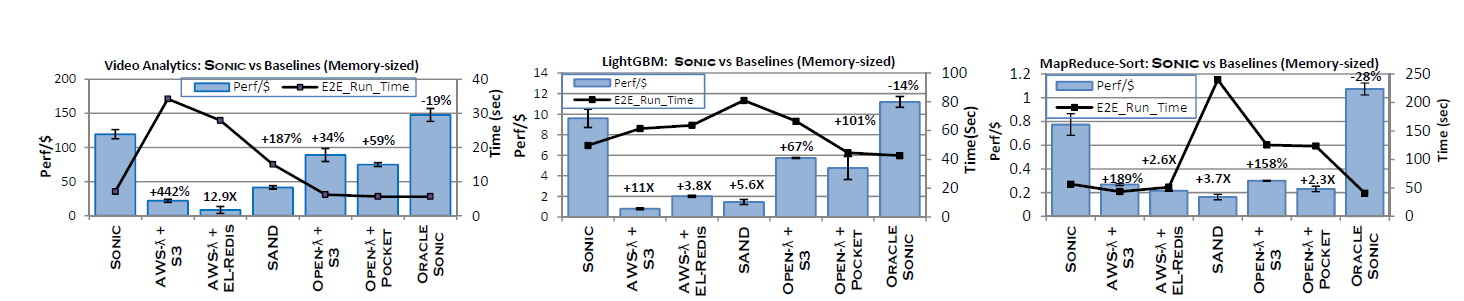
The Road Ahead
If serverless workflows are going to become mainstream, we need solutions to several rich problems, both conceptual innovations and practical instantiations of these. Here is a very subjective set that are uppermost in my mind. We need to be able to provide guarantees — in end-to-end latency and fault tolerance. We are far from there today. I would like to see the vendors peel back the curtain a little so that power end users can make better use of the infrastructure. This gets the pendulum to swing toward the VM-based infrastructure, but I am not advocating anywhere near that level of configurability. Just a wee bit control please.
[1] Reviewer D:
[ I reviewed a prior version of the paper and many comments below carry over from that review. I was broadly positive in my prior review, and see the revisions made as improving the work. In particular, I like the shift from using an ahead-of-time profiling phase to operating with on-line profiling with a basic S3-based implementation. ]
[2] Technically FaaS is a subset of serverless but that is a nuance that is often overlooked and is not important in our context.
[3] Markets and Markets, "Serverless Architecture Market," At: https://www.marketsandmarkets.com/Market-Reports/serverless-architecture-market-64917099.html, 2020.
[4] Hendrickson, Scott, Stephen Sturdevant, Tyler Harter, Venkateshwaran Venkataramani, Andrea C. Arpaci-Dusseau, and Remzi H. Arpaci-Dusseau. "Serverless computation with openlambda." In 8th {USENIX} Workshop on Hot Topics in Cloud Computing (HotCloud 16). 2016.
[5] Akkus, Istemi Ekin, Ruichuan Chen, Ivica Rimac, Manuel Stein, Klaus Satzke, Andre Beck, Paarijaat Aditya, and Volker Hilt. "{SAND}: Towards High-Performance Serverless Computing." In 2018 {Usenix} Annual Technical Conference ({USENIX}{ATC} 18), pp. 923-935. 2018.
[6] Klimovic, Ana, Yawen Wang, Patrick Stuedi, Animesh Trivedi, Jonas Pfefferle, and Christos Kozyrakis. "Pocket: Elastic ephemeral storage for serverless analytics." In 13th {USENIX} Symposium on Operating Systems Design and Implementation ({OSDI} 18), pp. 427-444. 2018.
