This post gives a high-level view of our Sigmetrics 2022 paper, which was recently announced at the conference as the best paper winner.
Ashraf Mahgoub, Edgardo Barsallo Yi (Purdue University), Karthick Shankar (CMU), Eshaan Minocha (Purdue University), Sameh Elnikety (Microsoft Research), Saurabh Bagchi, and Somali Chaterji (Purdue University). WISEFUSE: Workload Characterization and DAG Transformation for Serverless Workflows. ACM Sigmetrics Conference, Article 26 (June 2022), 28 pages.
Serverless computing has been one of the hot topics in cloud computing, now for 5+ years. Innovation continues to happen at a fast pace with academic publications at the top systems conferences and interest in the technology community [1]. One emerging topic is how serverless platforms can support more complex applications, rather than the one-shot short-running functions where the sweet spot of serverless has been so far. A logical way to think of such applications is that these are represented as Directed Acyclic Graphs (DAGs) where each node is a function and there is data and even control dependency across nodes.
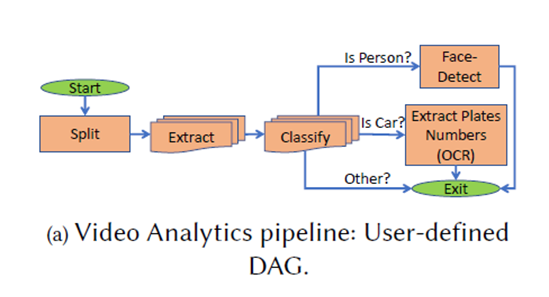
Within this emerging way, there is already support in the major cloud computing platforms, such as, through Amazon AWS Step Functions and Microsoft Azure Durable Functions. Through our analysis of Microsoft Azure traces (released as part of this paper), we find that the total number of DAG invocations per day has grown by 6× over the past 2.5 years, suggesting that this kind of workload is growing rapidly.
The Gap
Of course, someone wanting to run serverless applications would like to have some guarantees, probabilistic as it will have to be, on the time that the application will take to complete, and also on the $ cost that the application will consume. There was no solution to this till this work. There were two major challenges that had to be solved. First, the times for each function turn out to be distributions rather than point values (Figure 1). This happens due to multiple reasons, of which there are two primary reasons. The first one is that there is variation in execution times for a function, even a simple function, due to the fact that the execution time depends on the data. The second reasons is variability in the cloud computing infrastructure, such as, the fact that the network bandwidth available to a particular container or VM tends to change. The second challenge is that one needs to be able to determine the appropriate size of the container or VM considering the variability and to get the metric of interest (latency or $ cost) to meet the user service level agreement (SLA).
The Key Contributions
Our work represents the first step in what we expect will be a long road. The first advance is that we look at the execution times of individual functions and create a distribution for each function. We do not get into the root cause of that variation due to the practical difficulty of determining that. But the key takeaway is that there is enough variability that point estimates for rutimes of individual functions are not good enough to create a performance model for serverless DAGs. Next we combine distributions of multiple functions in a DAG taking into account the structure of the DAG — are these functions in series or in parallel, are these functions’ execution times correlated — to determine a distribution for the end-to-end (E2E) latency.
The second advance is that based on the above performance characterization, we determine what is the right size of the container within which to run an individual function or a bundle of functions. This has to be done considering the latency or $ cost objective. This was a challenge considering various heuristic rules that are present in cloud provider’s serverless offerings, e.g., in AWS Lambda network bandwidth saturates at 1792MB, irrespective of the size of the container you request, while in Google Cloud Functions, the bandwidth keeps growing as you request larger sized containers. The costs are also non-linear and the different resources (CPUs, memory, local and remote storage, network bandwidth) scale differently.
Workload Characterization from Microsoft Azure
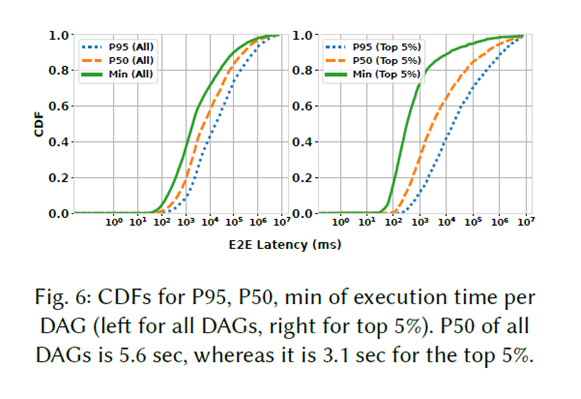
We did a detailed characterization of serverless DAG executions on Microsoft Azure, covering two weeks of production traces from six data centers, three in the US, two in Europe, and one in Asia. This analysis brought out some novel insights. First, 95% of the DAG invocations come from the 5% most popular DAGs. Second, the median execution time for all DAGs (i.e., median of medians) is 5.6 sec while there is a long tail —- ratio of P95 to median is 3X. Finally, we notice that both execution time skew and intermediate data size have a significant impact on the DAG E2E latency. This motivates our focus on these two factors to optimize through Bundling (reducing execution skew) and Fusion (reducing intermediate data passing latency).
Two Optimizations
The paper unveils two optimizations for reducing the E2E latency. The first is bundling multiple parallel invocations into a single function bundle to take advantage of execution time skew among these parallel workers. Then we assign just the right amount of resources (quantified through the size of the VM or container) to the function bundle. The second is fusing a series of functions into a single function executing on the same container. This cuts down on the data passing latency between these in-series functions.
So Does It Work?
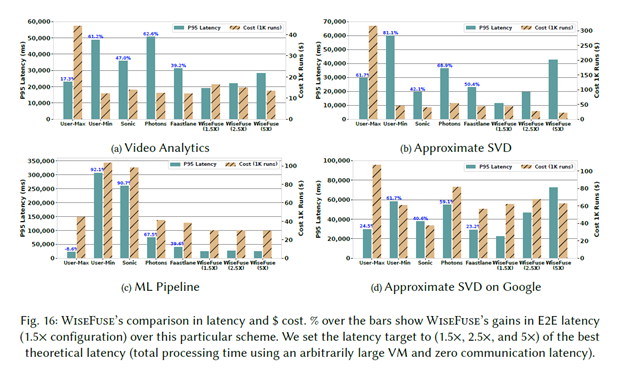
We did an evaluation of WiseFuse using three popular serverless applications with different DAG structures —- Video Analytics, ML Pipeline, and Recommendation engine. We find significant improvements in E2E latency and cost compared to four approaches from recent work —- the user-defined DAG, i.e., the state of practice, FaastLane [USENIX ATC 21], Sonic [USENIX ATC 21], and Photons [SOCC 20].
What’s Next?
I mentioned that this is an initial step in what I think will be a long journey of better supporting serverless DAGs. Most significantly, our work has a static feel to it —- once we characterize a DAG well, we can make rational decisions about whether to apply the optimizations and to what extent. But with workload changes, the DAG characteristics may change and it is an open problem, how one can make online decisions efficiently. This can borrow from the theme of online learning but many domain-specific challenges will have to be figured out. Another biggie is the security implication of applying optimizations within a single DAG or across DAGs, potentially belonging to multiple users.
[1] ACM DL had 67 papers in 2021 with "serverless" in its abstract, IEEE had 131. 5 years ago, those numbers were 3 and 6 respectively. According to Google Trends, there is 100% increase in interest in "serverless" from 2016 to now.
