We come across many algorithms in our education and work. Here I look at three relatively recent ones from the area of Machine Learning (ML), and more specifically from my vantage point of reliability and security of ML. There have been reams written on each, at various levels of technical depth. So obviously I am not looking to reprise them. Rather, this post is going to be a high-level look with emphasis on the applications that I see of them to reliability and security. The term that has gained ground for this sub-field is “assured autonomy”. If you have opinions on what other algorithms should be included, chime in.
Long Short Term Memory (LSTM)
We all love having reliable memories, both short term and long term. We also love our computing algorithms to have them. Before LSTMs came about, there was not a fully satisfactory way to achieve that. In many applications, most prominent of which is language processing, some elements from a little ways back can affect what the prediction for the next element will be. Closer to my area of work, many time series are such that some events farther back in time can have a predictive effect. This is what LSTMs allow us to model. Importantly, they do not have a kitchen sink full of parameters to tune, and retune every time even the faintest wind blows through my data set. Thus under a broad range of changes to the datasets, my earlier LSTM continues to work just fine.
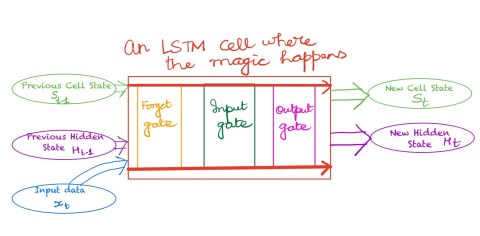
I find this algorithm to be quite valuable when detecting anomalies in time series data. Because of its predictive power, it can tell me what the near-term future will look like. And if the prediction and the actual observation differ by too much, I can let loose an algorithm to dig deeper — do a deeper inspection of the trends to try to uncover what went wrong (if anything) and when. Again, I like the conceptual simplicity of the LSTM model. Even though there are quite a few configuration parameters to choose from (form of the forget gate, combination of current input with previous state, etc.), the defaults work quite well in many cases. As a practitioner, I know when to leave well alone and so I can get to work incorporating the LSTM in the rest of my system.
I also like the fact that some simple and yet powerfully effective improvements to LSTMs come out at a fair clip. For example, the notion of bi-directional LSTMs are useful, not in my time series applications (we have not invented time travel yet, alas), but in some others like telling if a corpus of text is phishing or not. With the corpus of text, I can look earlier as well as after to get a clue about the current element, and so bi-directional LSTM is useful.
If I had to complain about LSTM (and I know I do not have to), I will say that it takes a while to run during inferencing. But this actually is a blessing in disguise. A systems person like me can play various approximation tricks to make the inferencing go faster.
Fed Average
Federated Learning came out as a hotshot creature out of the ML stable in 2017. Fed Average is this simple but wonderful, no, simple and wonderful, method to take the wisdom of the crowds to arrive at a great model, efficiently.
In its basics, all that Fed Average does is it collects the gradients from all the clients, which they calculate based on their local learning and local data. It then averages all these gradients and sends them out to all the clients. This is a nod to the tremendous power of decentralization, one of the enduring lessons of computing. You can try and build one super powerful computer, but you will always be overtaken by the power of many many wimpy devices working together.
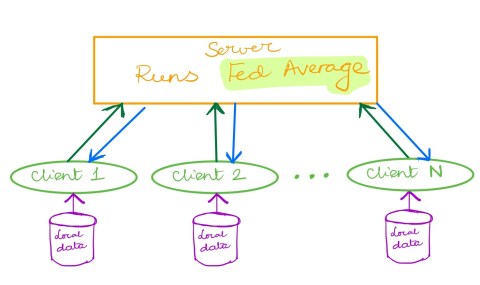
I also like Fed Average because it is a great playground for many to play on. It allows innovative solutions that can make this basic approach secure; secure to clients behaving badly, secure to some of the data being corrupted, and many other forms of threats. Thus, it is eminently customizable, while the default of mean averaging works well in a surprisingly diverse set of situations (where all parties are well behaved). These two properties — being customizable and having good defaults — are to me two essential properties of great algorithms.
Carlini-Wagner Attack against ML Classifiers
Rarely does the name of a colleague strike fear into the hearts of other researchers. This is one of those rare exceptions. Nicholas Carlini and David Wagner from Berkeley came up with this attack against ML classifiers in their IEEE Security and Privacy paper in 2017, and it goes by its universal nickname C-W. C-W dealt a crushing blow to all secure classifiers and has since become the standard against which any secure classifier has to pass muster. In this fast-moving field of secure ML, this algorithm has astonishingly held its sway as an essential part of the toolchest to evaluate any algorithm.
Like most great algorithms, this algorithm can be explained to anyone with basic computing literacy in the matter of a few minutes. It provides a method to generate adversarial examples (i.e., examples that are tailored to fool ML classifiers). It does this through a simple mathematical formulation where an optimization function is minimized. The function balances the two competing factors: one is how close does the adversarial example have to be to the original example (lower means it is easier to fool a simple rule-based classifier or even a human) and the second is how likely is it to flip the decision of the classifier (a higher value means the attack has higher likelihood of success). A single constant controls the tradeoff between these two.
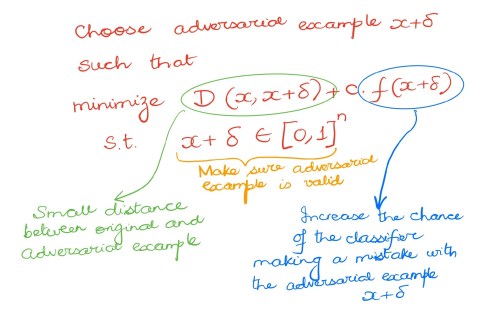
This algorithm, as I mentioned above, is the closest to a litmus test that exists in the field. It has been augmented with more sophisticated attacks, but it serves as a good starting point. If your algorithm crumbles when faced with C-W, then you better go back to the drawing board. Like the above two algorithms, it is customizable but does not let you drown in a sea of choices, and its defaults (L2-norm and default value of the trade-off constant) work well in practice.
The algorithm has also served to trigger much follow on work as it is quite expensive (time-wise) to generate adversarial examples using C-W. Thus algorithmic improvements and heuristic improvements have had a productive time making C-W faster.
To Sum
The area of security and reliability in ML is a flourishing one. It is in an intellectually exciting phase where there are still many pertinent and technically challenging questions being discovered and answered at a fast clip. It is a bonus that there are strong foundations for us to build on. The three algorithms touched upon here — LSTM, Fed Average, and Carlini Wagner — are part of this canon. They provide lessons to us on near universal features that great algorithms have.
